Borser cache 浏览器缓存机制
Mar 9, 2018通过网络获取内容既速度缓慢又开销巨大。较大的响应需要在客户端与服务器之间进行多次往返通信,这会延迟浏览器获得和处理内容的时间,还会增加访问者的流量费用。因此,缓存并重复利用之前获取的资源的能力成为性能优化的一个关键方面。
Borser cache 浏览器缓存机制
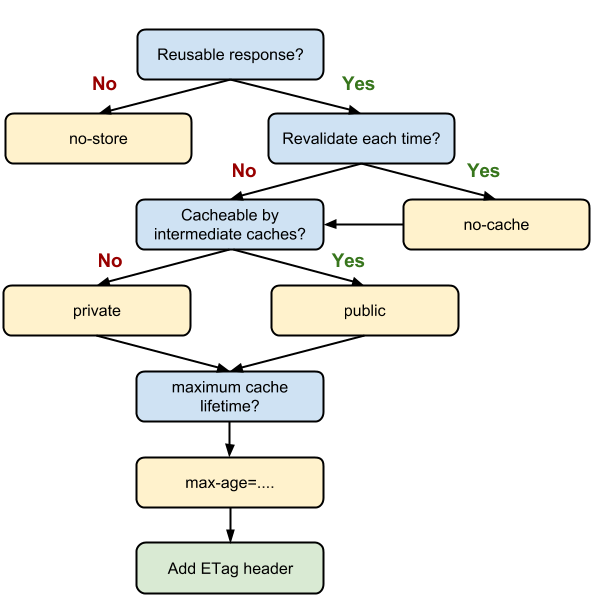
当浏览器需要下载一个文件的时候,首先回去缓存里面查找;如果能找到,若文件未过期,则直接获取文件,若文件以经过期,则向服务端发送一个http请求,请求里面带上(Cache-Control: no-cache,If-Modify-since: Fri, 09 Mar 2018 06:39:44 GMT, If-None-Match: 39d3f65bbb1a81810820fc0fad400c82),服务端接收到请求之后,校验相应的文件的修改时间或者Etag值(一般情况这两个校验只存在一个,etag比文件的修改时间更精确,后者只能精确到秒,如果文件在1s内被修改过,文件的最后修改时间就是一样的了),如果文件在服务端 判断为没有发生变化,则返回一个304状态码的响应,响应不包含文件内容,并且(Cache-Control: max-age=86400,If-Modify-since: Fri, 09 Mar 2018 06:39:44 GMT, If-None-Match: 39d3f65bbb1a81810820fc0fad400c82),浏览器收到响应之后,继续使用本地缓存的文件内容;如果文件在服务端判断为发生了变化,则返回200状态码,并且返回文件的内容,和重新设置文件缓存时间。
参考
Newest Posts